

In our previous post Data Processing Part 1 – Platforms On The Edge we explored the benefits offered by data pipelining tools, especially data on the edge and how this can be used to the benefit of platform owners.
With Splunk having recently announced Ingest Processor at .Conf 2024, in this post we wanted to delve deeper into the features offered by Splunk’s Edge and Stream Processor in comparison to another leading data processing option, Cribl Stream Suite.
Exploring Key Features
Cribl Stream
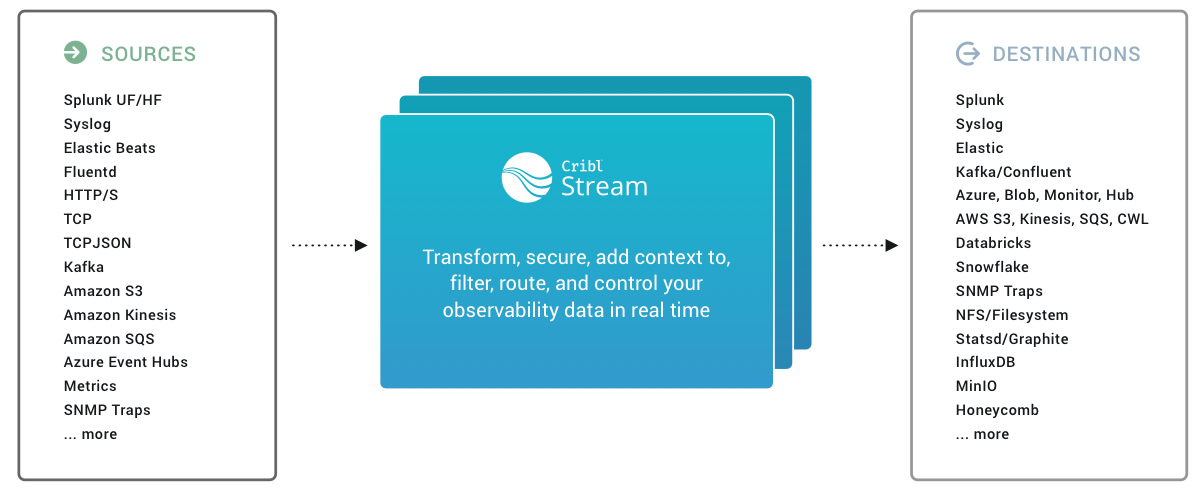
Cribl Stream is designed as a “streaming log data router,” providing extensive capabilities for transforming and routing data from multiple sources to various destinations, effectively optimising your data before it reaches your analytics tools or storage solutions.
Key Features of Cribl Stream:
- Data Routing and Enrichment: Allows for dynamic routing, transformation, and enrichment of data streams.
- Extensive Parsing Options: Supports a multitude of log formats and can parse structured and unstructured data effectively.
- Reduction and Filtering: Capable of reducing noise in the data, which can significantly decrease storage and processing costs.
- Plugin System: Offers a flexible plugin system that can extend functionality and integrate with various external systems and custom solutions.
- Product Agnostic: Can route data from any source to any analytics tool or storage solution desired.
- Available in the Cloud and On-premise: Available as a cloud product or can be installed locally in your data centres to reduce traffic sent out of your networks
- Replay Feature – Data in cold storage can be “replayed” back into your data analytics tools ensuring only the data you require is counting against your ingest licenses.
- Scalability – Horizontally scalable both on-premise and in the cloud.
Cribl Edge
Crible Edge is part of the Cribl Stream suite of products. It is a centrally controlled, vendor-neutral, lightweight “Edge” data collection agent able to route data to any destination. The product itself is comparable to Splunk Universal Forwarder, with many enhanced features.
Key Features of Cribl Edge
· Centrally Managed: Fleets of Cribl Edge nodes can be managed by a central console.
· Intelligent: Automatically discover log and metric data near its source. This allows data to be examined before deciding to collect and process it.
· Agnostic: Route data to any destination of your choice, including Cribl Stream for data processing.
· Observability for Kubernetes: Pre-packaged Cribl Edge helm charts grant enhanced visibility of Kubernetes deployments
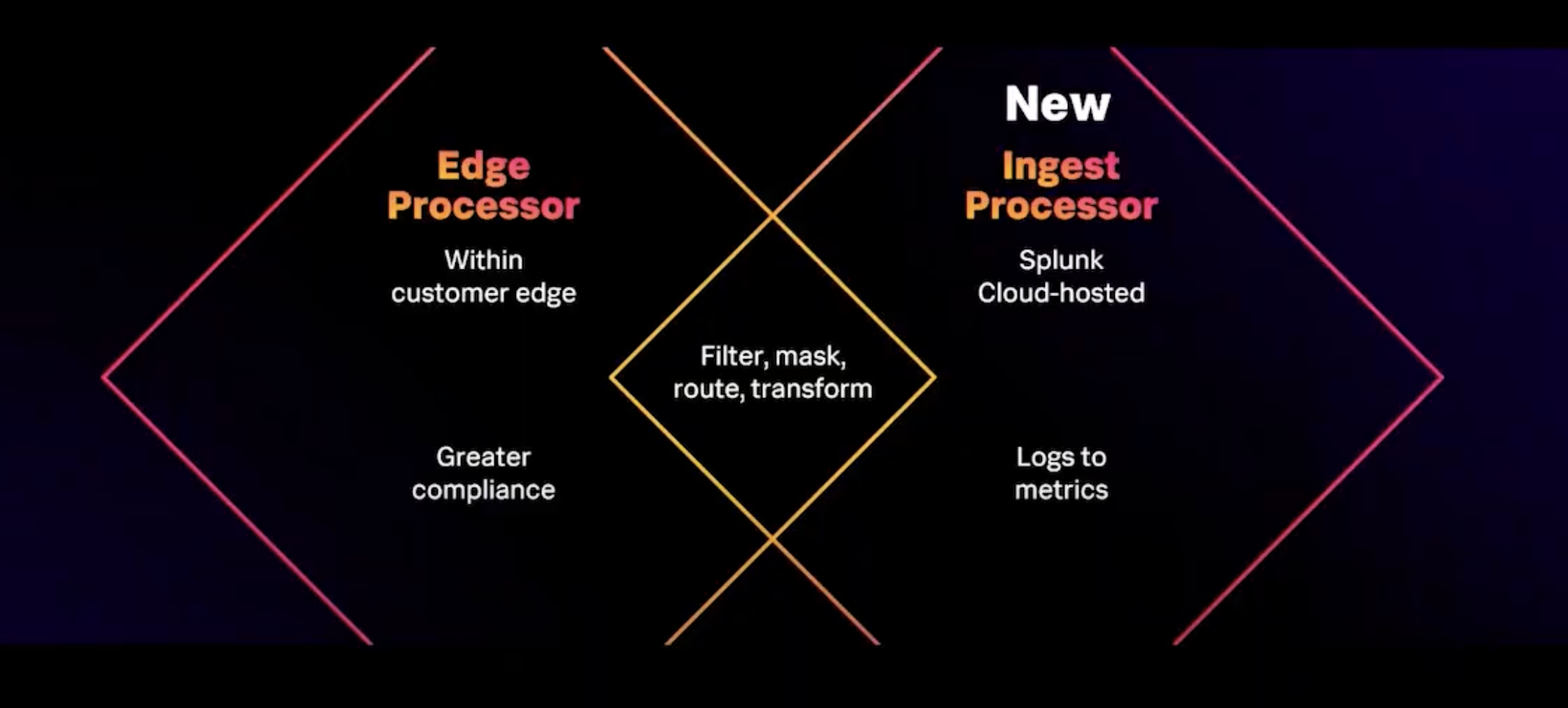
Splunk Edge Processor
As part of Splunk’s Data-to-Everything platform, the Splunk Edge Processor is a Cloud offering that enhances the capabilities of data processing at the edge of the network by installing Edge Nodes.
Key Features of Splunk Edge Processor:
- Local Processing: Edge Nodes act as an intermediate forwarding tier carrying out preliminary filtering, routing and data transformation close to the data source, reducing latency and bandwidth usage.
- Real-time Decision Making: Facilitates immediate operational decisions at the edge by providing real-time analytics and insights.
- Integration with Splunk: Seamlessly integrates with the broader Splunk ecosystem, maintaining a unified management and analytics experience.
- SPL2: Edge Processor makes use of the SPL2 language to make data transformation easy and flexible, especially for those familiar with SPL.
- Destinations: Edge processor can route to different Splunk destinations or cloud storage such as S3.
- Scalability – Scaling horizontally with more edge nodes is required for greater workloads.
Splunk Ingest Processor
The Splunk Ingest Processor is tailored to optimise data ingestion into Splunk by pre-processing it to ensure efficient indexing and storage.
Key Features of Splunk Ingest Processor:
- Ingest-time Transformations: Has the same filtering, routing and transformation capabilities as Edge Processor, aimed at efficiently reducing the load on the indexing tier and reducing data storage.
- Cloud: A fully cloud-based product which is fully integrated with Splunk deployments and placed in front of it.
- Scalability: Designed to handle large volumes of data efficiently, making it suitable for enterprise-scale deployments.
- Logs to metrics: Can convert logs into Splunk metric format
Comparing Cribl Stream with Splunk’s Offerings
Data Transformation: Both offerings allow data to be transformed, routed and filtered. Cribl uses built-in functions and code to build pipelines whereas the Splunk Processors use SPL2 which may be more intuitive to a Splunk user.
Data Management: While both platforms offer powerful data processing capabilities, Cribl Stream provides broader control over data routing and enrichment, beneficial for environments needing granular data manipulation. Splunk Edge Processor focuses more on the efficiency of data handling at the edge, optimizing for real-time insights.
Stage of Data Handling: Cribl Stream interacts with data across various stages of its lifecycle, from collection to routing to multiple destinations. The Splunk processors cover different stages of the lifecycle. Splunk Ingest Processor targets the ingestion stage, optimizing data before it is indexed in Splunk. Splunk Edge processor, as the name suggests, handles data closer to its source.
Flexibility and Integration: Cribl Stream’s architecture is inherently designed for flexibility and can integrate with multiple platforms and storage, not just Splunk. The Splunk Processors are highly optimised for Splunk environments, which might be a limitation if your architecture involves various analytics platforms.
Metrics: For environments that specifically make use of metrics in Splunk, Ingest Processor offers inbuilt conversion from logs to metrics, which offers a simpler solution to building a custom function in Cribl.
Conclusion
In the dynamic world of data processing for SIEM, understanding the specific capabilities and best use cases for tools like Cribl Stream, Splunk Edge Processor, and Splunk Ingest Processor is crucial. Whether you need robust edge data processing, efficient data ingestion, or a flexible data routing solution, choosing the right tool can significantly impact the effectiveness of your data strategy. Consider your organisational needs, existing IT infrastructure, and long-term data management goals when deciding between these advanced data processing solutions.



See how we can build your digital capability,
call us on +44(0)845 226 3351 or send us an email…